
【解説】1週間かかる調べものが一瞬で完了?!ウェブスクレイピングで確実に業務自動化

業務の中で、急に「調べもの」が必要なこと、意外と多いですよね。
特に、複数のウェブサイトを巡回して特定の情報を探すような作業は、時間がいくらあっても足りません。
たとえば「都道府県ごとに、ある団体の決算情報を調べて一覧化してほしい」という仕事があったとします。しかも対象は全国。これは相当ハードです。
・各県の公式サイトへアクセス
・決算書や事業報告がどこにあるか探す
・公開されているのか、対象年度があるのかを確認
・結果をまとめる

…という地味で膨大な作業。
普通にやれば数日、場合によっては1週間はかかるでしょう。さらに、人の手作業では “抜け漏れ” が出るリスクも避けられません。
そこで登場するのが「ウェブスクレイピング」
ウェブスクレイピングとは、ウェブサイトから必要な情報を自動で集める技術のことです。

人が画面をクリックして探すのではなく、プログラムが何百ページでも一瞬で巡回して必要な情報を抽出してくれる──そんなイメージです。
ここでは、実際に使用したPythonコードを例に、スクレイピングの仕組みを簡潔に解説していきます。(URLは伏せています)
使用するPythonライブラリの中心は BeautifulSoup です。
まずは「サイトを巡回する仕組み」をつくる
やることはシンプルです。
自動化の流れ
①サイトにアクセスする
②ページ内のリンクを全部抜き出す
③同じサイト内のページだけを深くたどる
④キーワード(例:決算・財務など)が含まれるページを記録する
⑤PDFやExcelを見つけたら保存対象にする
作成したPythonのコードを3分割して解説します。
1,【Step1】BeautifulSoupをインポートしてサイトにアクセスする
まずは巡回の土台となる部分です。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import time
import csv
target_sites = {
"北海道": "https://***********/",
"青森県": "https://***********/",
"岩手県": "https://***********/",
}
keywords = ["決算", "財務", "貸借対照表", "事業報告"]
file_extensions = [".pdf", ".xlsx", ".docx"]
}
keywords = ["決算", "財務", "貸借対照表", "事業報告"]
file_extensions = [".pdf", ".xlsx", ".docx"]
ここで「何を探すか?」を指定しています。
キーワードやファイル拡張子を変えるだけで、用途に応じて幅広い調査に応用できます。

2,【Step2】ページをどんどんたどって"欲しい情報"だけ抽出する仕組み
スクレイピングの核心はここです。

この処理では、主にBeautifulSoupによって、
・ページのHTMLを取得
・ページ内のすべてのリンクを抽出
・テキストに決算・財務などのキーワードが含まれているかを判定
・PDFやExcelなどの添付ファイルも判別
という流れで、目的の情報を確実に拾い上げていきます。
def fetch(url):
try:
res = requests.get(url, timeout=8)
res.raise_for_status()
return res.text
except:
return None
def extract_links(html, base_url):
soup = BeautifulSoup(html, "lxml")
links = []
for a in soup.find_all("a", href=True):
url = urljoin(base_url, a["href"])
links.append(url)
return links
def contains_keywords(text):
return [kw for kw in keywords if kw in text]
def is_document_link(url):
return any(url.lower().endswith(ext) for ext in file_extensions)
3,【Step3】47都道府県を“深い階層まで”自動クロールし、結果をCSVにまとめる
最後のフェーズです。
対象サイトを自動で巡回し、まだ見ていないページを順番に探索しながら、キーワードや添付ファイルを含むページを次々と記録していきます。
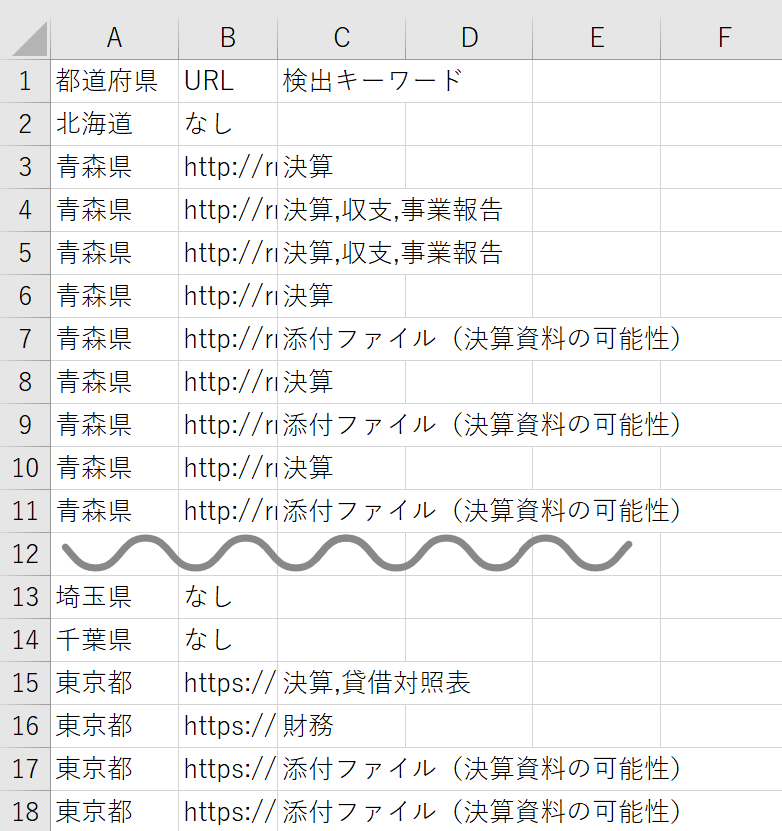
最終的には、都道府県ごとに整理された一覧がCSVで出力されます。

def crawl_all_levels(name, start_url):
visited = set()
to_visit = [start_url]
hits = []
while to_visit:
url = to_visit.pop(0)
if url in visited:
continue
visited.add(url)
# PDF・Excel・Word等
if is_document_link(url):
hits.append({"url": url, "keywords": ["添付ファイル"]})
continue
html = fetch(url)
if not html:
continue
found = contains_keywords(html)
if found:
hits.append({"url": url, "keywords": found})
for link in extract_links(html, start_url):
if link not in visited:
to_visit.append(link)
time.sleep(0.6)
return hits
all_results = {}
for name, url in target_sites.items():
all_results[name] = crawl_all_levels(name, url)
with open("results.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["都道府県", "URL", "キーワード"])
for name, hits in all_results.items():
for h in hits:
writer.writerow([name, h["url"], ",".join(h["keywords"])])
これで、
「どの県の、どのページに、どんな財務情報があるか」が一気に一覧化できます。
人力なら数日〜1週間 → スクリプトなら“数分”
普通なら、
・ページがどこにあるかわからない
・階層が深い
・同じサイト内に関連記事が散らばっている
・PDFが別のディレクトリに隠れている
・そもそも公開されていない
…こういった理由で、とにかく時間がかかります。

しかしスクレイピングを使うと、

・人が見落とすような階層もまるごとチェック
・キーワード判定で漏れゼロ
・PDFやExcelも確実に検出
・抜け漏れをほぼ完全排除
そして何より、
作業時間が一瞬で終わる。
“1週間コースの調査”が、コーヒーを飲んでいる間に終わる世界。それがスクレイピングです。

「調べ物に追われる仕事」から解放される世界へ
調査業務でよくあるお悩みは、
・時間がかかりすぎる
・人によって精度が違う
・数が多すぎて手が回らない
といったものですが、スクレイピングを活用すれば大きく改善できます。
もちろん、すべてのサイトで利用できるわけではなく、利用規約の遵守が前提です。
しかし、正しく使えば、
・調査業務の効率化
・ミス・抜け漏れの削減
・作業品質の均一化
・本来の業務に集中できる時間の創出
といった効果が期待できます。

「貴社の調査業務」も自動化できます
もし、
・取引先の情報を定期的に収集している
・特定ページの告示・公告を追いかけている
・競合情報を一覧化している
・定型調査に時間を奪われている
といった業務があるなら、同じ仕組みを導入するだけで、使える時間を何倍にも増やせます。
調査に追われる毎日から解放され、“人にしかできない価値創造”に時間を割けるようになります。
ヤマダITオフィスでは、
業務に合わせた簡易スクレイピング仕組みの導入支援も行っています。

難しい?小さなことでも一緒に考えましょう。
お気軽にご相談ください。

